
如何建立信用评分卡模型(一)——概述

写在前面
前段时间给某城市做了一套城市信用分,其中的故事一言难尽。好在现在空出时间来了,可以整理一下以前的项目经验了。作为一个身经百战的银(wai)行(bao)建模人员,有一些经验打算在这里稍作分享。一方面可以给需要的人以启发,另一方面也是笔者的自我复盘。
考虑到有些读者可能没接触过这类项目,笔者会从业务、数据和算法这些角度尽可能细致地讲。大佬请跳过。这一次就先做一个总体的概述吧。
信用评分卡是啥
评分卡模型是金融领域比较常见的模型。评分卡并不是什么特别高大上的东西,它其实就是一套打分规则。这里给出一个评分卡的例子:
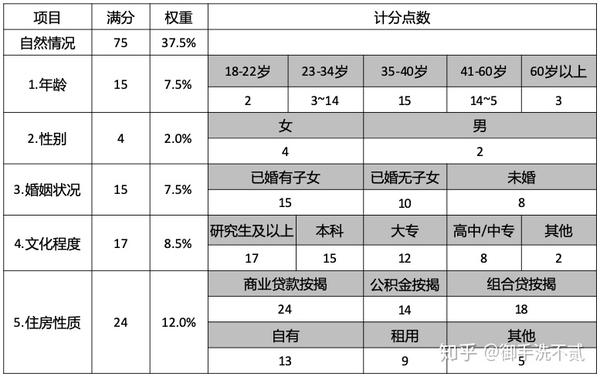

那么问题来了,这个打分规则是怎么确定的呢?
一种是经验规则(专家规则),另一种是靠机器学习模型算出来的。本文主要讲的是后者,即使用机器学习模型构建信用评分卡。
评分卡的类型
在风控领域,根据评分卡使用场景的不同,一般分为申请评分卡(A卡)、行为评分卡(B卡)和催收评分卡(C卡)。其中,A卡用于信贷申请(贷前)阶段,用于评估借款人的风险水平,从而决定是否放款;B卡用于还款(贷中)阶段,根据借款人的还款行为来预测借款人的风险变化;C卡用于催收(贷后)阶段,针对已经出现不良的贷款,评估其回收的可能性。
这三种评分卡在算法上区别不大,主要区别在于数据方面。其中A卡和另外两者的区别会更大一些,因为构建A卡时无法使用借款人的还款行为数据(贷款还没放,哪来的还款行为),也不需要对不同时间段的合同进行采样,这一点后面会详细解释。因此A卡相对于后两者更简单一些,相应地,准确性也会差一些。
常用算法
刚才我们提到了算法。在信贷领域,构建评分卡最常用的算法是逻辑回归算法。逻辑回归的优点是原理简单、调参简单,且模型结果的可解释性很强,可以很好地转化为量化的分数。关于逻辑回归的原理这里就不多说了,还不清楚的读者请移步刘建平老师博客:
建模数据集
现在,假定各位看官已经了解了逻辑回归。
那么我们来思考一个问题:在开始建模之前,我们第一步需要做什么?
当然是把数据搞到手。至于这个数据是谁提供过来的、怎么提供的,里面的坑只有做的人才能体会。
第二步就是明确模型的目标变量,即模型要预测什么。逻辑回归模型属于分类模型,用来预测样本属于什么类型。在金融领域,我们一般使用到的都是二分类的逻辑回归,它的目标变量是类别标签,即“0”和“1”。根据场景不同,它可以表示”是/否“、”好/坏“或”有/无“。
以A卡为例,它预测的是用户在申请贷款通过以后发生不良行为的概率,因此目标变量就是”贷款正常/出现不良“。我们一般把目标变量命名为“bad”,如果一条样本的bad等于1,就表示这条样本出现了不良行为,属于“坏”样本;bad等于0,表示这是一条“好”样本。
不良行为的标准是什么呢?这个我们留着以后再聊。
在确定了目标变量以后,我们还需要选择自变量。通常情况下,原始数据集中的变量几乎都不能直接入模,需要进行数据清洗。可以参考笔者的这篇文章:
特征工程
完成数据清洗后,我们是否就可以开始模型训练啦?并不是。在训练模型之前非常重要的一步叫做特征工程。特征工程是对原始数据进行进一步的处理、运算并生成新的变量,目的是帮助模型更好地识别数据中包含的统计规律。
另外,特征工程中还有一步非常重要,即变量分箱(Binning)。变量分箱是对连续变量进行离散化,即将连续变量划分为若干个区间,每个区间赋予相同的值。这句话可以拆解为三个问题。
首先,为什么要离散化?离散化最重要的作用是增加模型的鲁棒性,提高模型的泛化能力。连续型变量往往内部存在异常值,通过变量分箱可以消除异常值的干扰。而且变量分箱可以把缺失值划为单独的类进行处理,降低了缺失值对模型的影响。
其次,若干个区间该怎么划分?业界常用的方法是卡方分箱和决策树分箱。关于两者的原理,这里不多做解释,网上有许多成熟的代码可以直接引用。多说一句,作为数据从业人员,最重要的能力就是信息获取,不然会累死的。
最后,分箱后每个区间该赋什么值?在这里需要掌握两个概念,WOE值和IV值。受篇幅所限,这两者以后我们再详细解释。
模型训练
训练模型时,我们需要将输入的数据集划分为训练集和测试集两部分。它们分别占原数据集的70%或30%(按60%、40%分也可以)。其中,训练集用于训练模型,得出模型参数;测试集用于检验模型的拟合能力,防止过拟合或欠拟合。
在算法选择方面,我们通常使用二分类逻辑回归。逻辑回归的好处是可以输出概率值,这个概率值可以通过一定的运算转化为评分卡分数。
而且逻辑回归的解释性要好于GBDT等集成算法,它可以直观地看到每一个变量对预测结果的影响大小。在模型实现方面,我们可以直接使用Python第三方库sklearn或statsmodel中的LogisticRegression方法,具体的代码可以上网查询。在这里推荐刘建平老师的技术博客:
将数据输入模型,我们可以得到初步的模型参数。关于模型的参数调整,我们后续再做深入讨论。模型的结果差不多长这样:
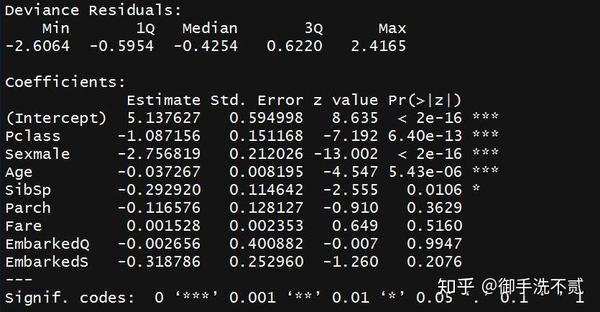

接下来算分数的时候会用到estimate这项,即各变量的系数。
模型评价
在计算分数之前,还有一个重要步骤要做。我们需要对上述模型的效果进行评价,确定它是否可以有效地对样本进行分类。常用的指标有KS、AUC值和Gini系数等。这三个指标具体是什么含义、怎么算出来的,我们以后详细讨论。
以KS值为例,在申请评分卡模型中,通常情况下KS一般取值范围在25-45之间。如果低于25,说明模型的区分度太低,分类不准确;如果高于45,则模型可能存在过拟合,对新样本的预测能力不一定会好。
分数校准
模型计算出的结果是概率值,即该借款人后续出现坏账的概率,取值范围是0到1。为了构建评分卡,我们需要对概率进行放大,将概率转化为分数。单个样本总得分的计算方法如下:
Offset = 基准分 - Factor * ln(Odds)
Factor = Pdo / ln(2)
校准分数 = Offset + Factor * ln((1-prob) / prob)
上述过程计算的是单个样本的总分。评分卡要求我们提供每一个变量当中每一个分组对应的子评分。子评分的计算方法如下:
子评分 = Offset / N - Factor * (Intercept / N + WOE * 变量系数)
通过推导不难发现,子分数的计算和总分的计算是等价的。暂且先不用纠结这些公式都是什么含义,只需要先知道评分卡的分数是这么算出来的即可。通过上述公式,我们可以把0-1的概率值转化为任意取值范围,例如0-100分、350-950分等等。业务人员使用这个分数即可判断借款人的风险水平。
至此,我们就完成了一个申请评分卡的模型开发。在开发完成后,往往还需要配合工程人员完成上线部署。作为建模人员,需要提供的是入模变量的来源、计算逻辑和模型输出的评分卡。模型上线以后并不是就万事大吉了,还需要对上线后的模型进行观察和验证,并根据业务的发展对模型进行调整甚至重新训练。
写在最后
本文其实并没有讲细节的内容,只是从总体上概括了评分卡的建模思路和流程。读者朋友们可以把本文当做一篇引言,用来形成大体的思路。事实上,评分卡模型的建模涉及很多需要展开讲述的内容,如果通过一篇文章讲完的话,文章的结构会比较臃肿,很容易使读者云里雾里、首尾不能相顾。笔者后续会通过一系列文章详细阐述本文未尽之事宜。最后,感谢您读完本篇,有任何相关问题欢迎私信交流。
文章被以下专栏收录
