
解密AI个性化打分算法(二):智能打分函数

本文由方便面AI面试技术专家陨墨编辑(8年机器学习/数学/统计研究经验),转载请注明出处。
智能打分算法
从单项维度得分到面试者总得分
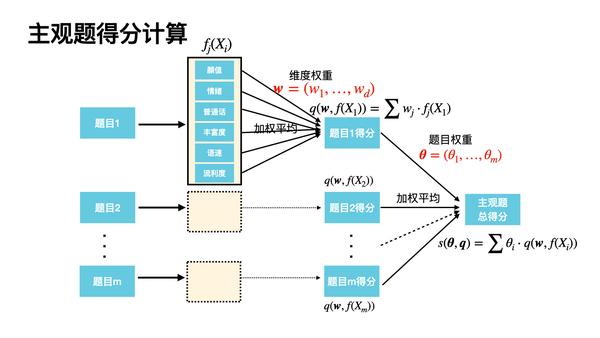
针对一道主观题回答视频 X_i ,通过单项维度打分算法将会产生6个维度的得分,分布对应颜值,情绪,普通话,丰富度,语速。用 f_i(X_j) 表示回答视频X_i在维度j上的得分,该题目最终得分q_i为所有维度打分的加权平均,即
题目得分 = \sum维度权重\times维度得分 q_i(\mathbf{w},f(X_i)) = \sum_{j = 1}^{d} w_j \cdot f_i( X_j) 其中\mathbf{w} = (w_1, \ldots,w_d)表示维度权重,要求 w_i \geq 0, \quad \sum_{i = 1}^{d} w_i = 1
在得到每道题得分q_i的基础上,主观题总得分为所有题目得分的加权平均 面试得分 = \sum题目权重\times题目得分
第i道题目对应的系数或权重可以用\theta_i表示,则面试者的总得分s 可以通过\boldsymbol{q} = (q_1,\ldots,q_m)的线性表达式来表示,即 s\left(\boldsymbol{\theta}, \mathbf{q}\right) = \sum_{i = 1}^m \theta_i q_i
在标准化面试打分系统中,用户通过设置每道题目维度权重 \boldsymbol{w} 以及对应的题目权重\boldsymbol{\theta},对每一名候选人可以计算出总得分s(\boldsymbol{\theta},\boldsymbol{q})。总得分越高,面试者表现越好。

损失函数(loss function)
在建立模型可以计算候选人总得分之后,我们通过损失函数将面试者的得分与实际录取结果建立关联。损失函数衡量了模型预测结果与实际结果的差别,模型效果越好,模型损失函数的数值越小。同时,在题目权重系数\theta_1, \ldots, \theta_m的基础上,我们添加一个截距项\theta_0, 一般\theta_0 < 0,最终得分可表示为 s\left(\boldsymbol{\theta}, \mathbf{q}\right) = \sum_{i = 1}^m \theta_i q_m + \theta_0
我们通过sigmoid函数将总得分映射为(0,1)区间内的一个概率,用H(\theta,q(w,f(\mathbf{X}))表示,也可以简写为\hat{y}。
\hat{y} = H(\theta,\boldsymbol{q}(w,f(\mathbf{X}))= \dfrac{\exp(s\left(\boldsymbol{\theta}, \mathbf{q}\right))}{1 + \exp\left(s\left(\boldsymbol{\theta}, \mathbf{q}\right)\right)}
\hat{y} 可以理解为面试者通过面试的概率,总得分越高,通过面试的概率越大\hat{y}越接近1。
在数据中,用y表示实际面试结果,取值0或1, y=1 表示通过, y=0 表示淘汰。我们希望预测概率\hat{y}与实际录取结果 y 接近,通过比较预测录取概率\hat{y}和实际录取结果y,建立损失函数。直观的方法是直接把模型错误率作为损失函数,但这种损失函数不是关于模型参数的连续函数,在模型参数优化上会有很大的障碍。 这里我们用 binary cross entropy (BCE)作为loss function l(y,\hat{y}) = -\left\{y \cdot \log(\hat{y}) + (1 - y) \cdot \log(1-\hat{y})\right\}
- 如果候选人实际被录取,即y = 1,那么损失函数l(y,\hat{y}) = - \log(\hat{y})。这时如果预测概率\hat{y}越接近1,loss function l(y,\hat{y}) 的值越小。反之如果 \hat{y}越接近0,loss的值越大。
- 如果y=0,那么l(y,\hat{y}) = - \log(1 - \hat{y})。这时如果 \hat{y}越接近0,loss function l(y,\hat{y}) 的值越小,反之如果 \hat{y}越接近1,loss的值越大。 数据集中包含m条数据,每条都是候选人面试数据X与标注结果 y 成对出现。最终损失函数L(\theta,\boldsymbol{w})所有每一条数据损失函数的平均,可以视为一个关于维度权重 \boldsymbol{w} 以及题目权重 \boldsymbol{\theta} 的函数 L(\theta, \mathbf{w}) =- \dfrac{1}{m}\sum_{\mathbf{x},y} \left\{y \cdot \log(H(\theta,q(w,f(\mathbf{X}))) + (1 - y) \cdot \left(1 - \log(H(\theta,q(w,f(\mathbf{X})))\right) \right\}
完成损失函数建立后,我们希望通过算法优化找到合适维度权重 \boldsymbol{w} 以及题目权重 \boldsymbol{\theta} ,使得损失函数 L(\theta,\boldsymbol{w}) 达到最小。


方便面是一家人工智能企业,目前有方便面AI视频面试、直播招聘、ATS智能招聘管理系统三款产品,主要针对企业招聘面试流程难点提出解决方案,为企业提供雇主品牌建设、人才获取、招聘流程自动化、人才沉淀等服务,用科技助力为企业智能化招聘提供支持。
文章被以下专栏收录
